doc up
44
apps/IntelliJ IDEA/IDEA 中启动多个微服务(开启 Services 管理).md
Normal file
@ -0,0 +1,44 @@
|
||||
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [blog.51cto.com](https://blog.51cto.com/yszr/2820700)
|
||||
|
||||
> IDEA 中启动多个微服务(开启 Services 管理),方法一、微服务项目的开发过程中,工程会非常多,经常要启动很多个服务,才能完成一项测试。
|
||||
|
||||
### 方法一、
|
||||
|
||||
微服务项目的开发过程中,工程会非常多,经常要启动很多个服务,才能完成一项测试。启动的多了,容易开发者带来错乱的感觉,很不方便管理。在 idea 作为开发工具时,推荐一个很好用的功能 --Run Dashboard,新版本里面的名字改成了 Services
|
||||
|
||||
.idea > workspace.xml 中添加如下配置,重启 idea
|
||||
|
||||
```
|
||||
<component >
|
||||
<option >
|
||||
<set>
|
||||
<option value="SpringBootApplicationConfigurationType" />
|
||||
</set>
|
||||
</option>
|
||||
<option >
|
||||
<list>
|
||||
<RuleState>
|
||||
<option />
|
||||
</RuleState>
|
||||
<RuleState>
|
||||
<option />
|
||||
</RuleState>
|
||||
</list>
|
||||
</option>
|
||||
</component>
|
||||
|
||||
```
|
||||
|
||||
此外,“ _运行_ / _调试”_ 工具窗口现在有一个名为 “ _端点”_ 的选项卡。此选项卡显示有关信息_健康_和_豆类_端点
|
||||
|
||||

|
||||
|
||||
### 方法二、
|
||||
|
||||
1. 点击菜单栏:Views -> Tool Windows -> Services;中文对应:视图 -> 工具窗口 -> 服务;快捷键是 Alt + F8,但是本地快捷键可能冲突,并未成功
|
||||
|
||||

|
||||
|
||||
2. 刚创建好的窗口是空白的,需要我们把服务加进去。也是比较简单:点击最右侧加号`Add Service`,选择`Run Configuration Type`,最后选择`SpringBoot`,IDEA 就会把所有项目加进来了
|
||||
|
||||

|
||||
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
{kind=link}
|
After Width: | Height: | Size: 11 KiB |
{kind=link}
|
After Width: | Height: | Size: 11 KiB |
BIN
apps/IntelliJ IDEA/assets/resize,m_fixed,w_1184.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 12 KiB |
BIN
git/assets/8jMmax.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 8.7 KiB |
BIN
git/assets/A87zPe.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 7.0 KiB |
BIN
git/assets/BIqlQW.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 4.3 KiB |
BIN
git/assets/BUiz44.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 9.1 KiB |
BIN
git/assets/HepjTM.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 4.8 KiB |
BIN
git/assets/J0Zku9.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 8.3 KiB |
BIN
git/assets/KmsbrV.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 4.1 KiB |
BIN
git/assets/LTzh9p.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 8.9 KiB |
BIN
git/assets/M9PM7Q.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 6.6 KiB |
BIN
git/assets/PDdv1I.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 9.2 KiB |
BIN
git/assets/QpdH5g.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 3.3 KiB |
BIN
git/assets/RQ39Rv-167247781367949.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 4.1 KiB |
BIN
git/assets/RQ39Rv.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 4.1 KiB |
BIN
git/assets/Sklh3v.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 9.9 KiB |
BIN
git/assets/UBCOSo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 8.5 KiB |
BIN
git/assets/dgYPmX.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 8.7 KiB |
BIN
git/assets/g9NjTO.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 16 KiB |
BIN
git/assets/hkVfzT.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 10 KiB |
BIN
git/assets/o9hGJa.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 6.3 KiB |
BIN
git/assets/wOR7JK.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 3.3 KiB |
BIN
git/assets/yIaYHq.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 5.9 KiB |
259
git/图解 Git 基本命令 merge 和 rebase.md
Normal file
@ -0,0 +1,259 @@
|
||||
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [www.cnblogs.com](https://www.cnblogs.com/michael-xiang/p/13179837.html)
|
||||
|
||||
Git 基本命令 merge 和 rebase,你真的了解吗?
|
||||
|
||||
前言[#](#1952709178)
|
||||
------------------
|
||||
|
||||
Git 中的分支合并是一个常见的使用场景。
|
||||
|
||||
* 仓库的 bugfix 分支修复完 bug 之后,要回合到主干分支,这时候两个分支需要合并;
|
||||
* 远端仓库的分支 A 有其他小伙伴合入了代码,这时候,你需要和远端仓库的分支 A 进行合并;
|
||||
|
||||
以上只是列举了分支合并的一些常见场景,关于 `merge` 和 `rebase` 命令你足够了解吗?
|
||||
|
||||
HEAD 的理解[#](#1939069430)
|
||||
------------------------
|
||||
|
||||
在介绍本文的主要内容之前,我们先理解一下 `HEAD` 。
|
||||
|
||||
`HEAD` 指向**当前所在的分支**,类似一个活动的指针,表示一个「引用」。例如当前在 `develop` 分支,`HEAD` 内容就是 `ref: refs/heads/develop`。
|
||||
|
||||
`HEAD` 既可以指向「当前分支」的最新 `commit`,也可以指向历史中的某一次 `commit` (「分离头指针」的情况)。归根结底,`HEAD` 指向的就是某个提交点。
|
||||
|
||||
当我们做分支切换时,`HEAD` 会跟着切换到对应分支。
|
||||
|
||||
fast-forward 与 --no-ff 的区别[#](#98971869)
|
||||
----------------------------------------
|
||||
|
||||
假如有一个场景:有两个分支,master 分支和 feature 分支。现在,feautre 分支需要合并回 master 分支。
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/wOR7JK.png)
|
||||
|
||||
`fast-forward` 合并方式是**条件允许**的情况,通过将 master 分支的 HEAD 位置移动到 feature 分支的最新提交点上,这样就实现了快速合并。这种情况,是不会新生成 commit 的。
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/QpdH5g.png)
|
||||
|
||||
`--no-ff` 的方式进行合并,master 分支就会新生成一次提交记录。
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/BIqlQW.png)
|
||||
|
||||
> 如果条件满足时,merge 默认采用的 `fast-forward` 方式进行合并,除非你显示的加上 `--no-ff` 选项;而条件不满足时,merge 也是无法使用 `fast-forward` 合并成功的!
|
||||
|
||||
merge 操作[#](#2315086939)
|
||||
------------------------
|
||||
|
||||
上面用图解的方式介绍了 `fast-forward` 和 `--no-ff` 的区别。下面,结合实际的代码仓进行合并操作,举几个栗子理解一下。
|
||||
|
||||
> `git merge` 操作是区分上下文的。**当前分支始终是目标分支**,其他一个或多个分支始终合并到当前分支。这个注意点记住了,方便记忆!所以,当需要将某个分支合并到目标分支时,需要先切到目标分支上。
|
||||
|
||||
### fast-forward 合并[#](#856326221)
|
||||
|
||||
刚刚一直在强调条件允许的时候,`fast-forward` 才能合并成功。条件指的是什么呢?
|
||||
|
||||
其实指的是源分支和目标分支之间没有分叉(单词 `diverge`),这种情况才可以进行快速合并。如果是下图中的场景,无法通过 HEAD 的快速移动实现分支的合并!
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/RQ39Rv.png)
|
||||
|
||||
下面进行一个不分叉的场景的示例:
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/A87zPe.png)
|
||||
|
||||
现在需要将 feature 分支合入到 master 分支,默认使用 `fast-forward` 方式:
|
||||
|
||||
```
|
||||
# 切到目标分支
|
||||
git checkout master
|
||||
git merge feature
|
||||
|
||||
|
||||
```
|
||||
|
||||
命令行里显示了 `Fast-forward` 的提示:
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/J0Zku9.png)
|
||||
|
||||
看一眼 master 分支合入的前后对比(注意 HEAD 的位置):
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/KmsbrV.png)
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/M9PM7Q.png)
|
||||
|
||||
### no-ff 合并[#](#2340007676)
|
||||
|
||||
不分叉的场景是否可以强制采用 `--no-ff` 方式合并呢?可以!
|
||||
|
||||
```
|
||||
# master 回到合入前的状态
|
||||
git reset --hard d2fa1ae
|
||||
git merge feature --no-ff
|
||||
|
||||
|
||||
```
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/LTzh9p.png)
|
||||
|
||||
这次命令行没有 `Fast-forward` 的提示了。
|
||||
|
||||
看一眼 master 分支图:
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/Sklh3v.png)
|
||||
|
||||
这个图和上面讲解 `no-ff` 命令时的示意图一致,果然会有新 `commit` 生成。
|
||||
|
||||
### 分叉场景的合并[#](#3682856066)
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/X69y67.png)
|
||||
|
||||
上面的图展示了我们经常遇到的一个场景,特性分支创建之后,源分支也会有新的提交。这就是形成分叉了。
|
||||
|
||||
这时候如果我们进行合并呢?
|
||||
|
||||
```
|
||||
git merge feautre
|
||||
|
||||
|
||||
```
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/g9NjTO.png)
|
||||
|
||||
可以看到,虽然默认会尝试 `fast-forward` 的方式进行合并,但是因为分叉了,所以此时会采用 `no-ff` 的方式进行合并!有新的 `commit` 生成了!
|
||||
|
||||
> fast-forward 方式对应的合并参数是 `--ff`
|
||||
|
||||
我们试试这个参数 `--ff-only`,顾名思义,就是强制只使用 `ff` 方式进行合并:
|
||||
|
||||
```
|
||||
# 回到合并前
|
||||
git reset --hard 3793081
|
||||
git merge feature --ff-only
|
||||
|
||||
|
||||
```
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/yIaYHq.png)
|
||||
|
||||
经过测试,当分叉时,因为无法使用 `ff` 方式合并,即使你强制指定使用该方式合并也不行,会提示终止!
|
||||
|
||||
附上 Git 官方文档中的解释,方便理解:
|
||||
|
||||
```
|
||||
With --ff, when possible resolve the merge as a fast-forward (only update the branch pointer to match the merged branch; do not create a merge commit). When not possible (when the merged-in history is not a descendant of the current history), create a merge commit.
|
||||
|
||||
|
||||
```
|
||||
|
||||
rebase 操作[#](#3837433697)
|
||||
-------------------------
|
||||
|
||||
`rebase` 命令是一个经常听到,但是大多数人掌握又不太好的一个命令。`rebase` 合并往往又被称为 「变基」,我称为 「基化」🤣。「基」的理解很重要,理解了它,其实 `rebase` 命令你就掌握了。
|
||||
|
||||
我的描述可能并不准确,只是为了能够帮助你理解。这里的「基」就是一个「基点」、「起点」的意思。「变基」就是改变当前分支的起点。**注意,是当前分支!** `rebase` 命令后面紧接着的就是「基分支」。
|
||||
|
||||
变基前:
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/RQ39Rv.png)
|
||||
|
||||
`git reabse master feature` 变基后:
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/HepjTM.png)
|
||||
|
||||
> git rebase 命令通常称为向前移植(`forward porting`)。
|
||||
|
||||
### 变基提交示例[#](#579017063)
|
||||
|
||||
我们接下来进行实际的测试,将代码库状态构造成分叉的状态,状态图如下:
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/o9hGJa.png)
|
||||
|
||||
以 master 分支为基,对 feautre 分支进行变基:
|
||||
|
||||
```
|
||||
git checout feature
|
||||
git rebase master
|
||||
|
||||
|
||||
```
|
||||
|
||||
以上两行命令,其实可以简写为:`git rebase master feature`
|
||||
|
||||
> 特性分支 feature 向前移植到了 master 分支。经常使用 git rebase 操作把本地开发分支移植到远端的 `origin/<branch>` 追踪分支上。也就是经常说的,「把你的补丁变基到 xxx 分支的头」
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/8jMmax.png)
|
||||
|
||||
可以发现,在 master 分支的最新节点(`576cb7b`)后面多了 2 个提交(生成了新的提交记录,仅仅提交信息保持一致),而这两个提交内容就是来自变基前 feature 分支,feature 分支的提交历史发生了改变。
|
||||
|
||||
观察上图还可以发现,变基后,改变的只是 feature 分支,基分支(master 分支)的 HEAD 指针依然在之前的 commit (`576cb7b`)处。这时候要将 feature 分支合入到 master 分支上,就满足 `fast-forward` 的条件了,`master` 分支执行快速合并,将 HEAD 指针指向刚刚最新合入的提交点:
|
||||
|
||||
```
|
||||
git checkout master
|
||||
git merge feature
|
||||
|
||||
|
||||
```
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/BUiz44.png)
|
||||
|
||||
看下图 master 分支图,观察 HEAD 指针的位置:
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/dgYPmX.png)
|
||||
|
||||
rebase 变基操作最适合的是本地分支和远端对应跟踪分支之间的合并。这样理解可能会更清晰一点。比如,远端仓库里有一个特性分支 feature,除了你开发之外,还有其他人往这个分支进行合入。当你每次准备提交到远端之前,其实可以尝试变基,这时候基分支就是远端的追踪分支。
|
||||
|
||||
下图是仓库的分支图:
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/PDdv1I.png)
|
||||
|
||||
```
|
||||
git fetch
|
||||
git rebase origin/feature feature
|
||||
|
||||
|
||||
```
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/UBCOSo.png)
|
||||
|
||||
观察上图,我们本地的提交以远端分支的最新提交为「基」,将差异提交重新进行了提交!远端分支的提交记录依然是一条直线~ 如果分叉的情况,不采用这种「变基操作」,而直接采用 `merge` 的方式合并,就会有如下这种分支提交图:
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/hkVfzT.png)
|
||||
|
||||
因为分叉了,采用 `git pull` 时也没法 `fast-forward` 合并,只能采用 `no-ff` 方式合并,最后的提交历史就会像上图那样。会产生一个合并提交。同时,分支图也显得稍微杂乱了一点,因为 feature 分支不是一条直线了。但是,其实也有好处,可以实际的看出来合并的提交历史。该选择哪个,往往取决于团队的选择策略。
|
||||
|
||||
### rebase 总结[#](#2277554924)
|
||||
|
||||
`rebase` 命令其实关键在于理解「基」,`git rebase <基分支>`,就是将当前基分支与当前分支的差异提交获取到,然后在「基分支」最新提交点后面将差异提交逐个再次提交,最后将当前分支的 HEAD 指针指向最新的提交点。
|
||||
|
||||
「基分支」的 HEAD 位置是不变的。要想完成分支合并,完成变基之后,需要再进行分支间的合并等操作。
|
||||
|
||||
rebase 命令的用法也不止于此,计划后期会专门写一篇介绍她的文章。本文本来是计划介绍 merge 命令的,但是合并的方式中,其实也经常涉及变基操作之后的合并,因此,干脆就放一起比较好了,这样易于理解记忆。
|
||||
|
||||
补充[#](#849436669)
|
||||
-----------------
|
||||
|
||||
* `git merge --abort` 当合并的过程中,由于冲突难解决,你想放弃合并,回到未合并之前的状态;
|
||||
* `git log --graph --pretty=oneline --abbrev-commit` 可以在命令行方便地查看提交图
|
||||
|
||||
一言[#](#2974805274)
|
||||
------------------
|
||||
|
||||
在 Git 这个专辑里有一篇介绍 cherry-pick 的文章,有个小伙伴给了如下的留言,说明自己分享的内容获得了肯定,欣慰啊!
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/vhpyi8.png)
|
||||
|
||||
今天肝的这篇文章,介绍了 Git 中的 merge 和 rebase 的基本概念和用法,同时,又自己手动绘制了图!俗话说,一图胜千言,但写完才发现,是真的耗时啊…… 不过,总结绘图的过程,自己也加深了理解,有些概念也变得更加清晰了!希望,我的总结也能让其他人读懂~
|
||||
|
||||
之前我经常会开启文章的「赞赏」,但发现收效甚微,很少有小伙伴会打赏。后来我就每次发文就关闭了这个选项。本文应该是 6 月份的「月末总结」了,就开启一次「月末赞赏」吧!期待小伙伴的支持与鼓励!
|
||||
|
||||
参考[#](#2616863506)
|
||||
------------------
|
||||
|
||||
我将本文的参考文章也都注明了,他们也都很有阅读的价值。但由于微信外链的缘故,可以点击右下角的「阅读原文」浏览!
|
||||
|
||||
* [StackoverFlow-What is the difference between `git merge` and `git merge --no-ff`?](https://stackoverflow.com/questions/9069061/what-is-the-difference-between-git-merge-and-git-merge-no-ff)
|
||||
* [git-scm-git-merge](https://git-scm.com/docs/git-merge)
|
||||
* [分支的合并](https://backlog.com/git-tutorial/cn/stepup/stepup1_4.html)
|
||||
* [Gitlab-Fast-forward merge requests](https://docs.gitlab.com/ee/user/project/merge_requests/fast_forward_merge.html)
|
||||
* [颜海镜 - 图解 4 种 git 合并分支方法](https://yanhaijing.com/git/2017/07/14/four-method-for-git-merge/)
|
||||
|
||||
> 生命不息,折腾不止!关注 「Coder 魔法院」,祝你 Niubilitiy !🐂🍺
|
||||
|
||||
[](https://gitee.com/michael_xiang/images/raw/master/uPic/%E5%85%AC%E4%BC%97%E5%8F%B7-%E4%BA%8C%E7%BB%B4%E7%A0%81-%E6%88%AA%E5%9B%BE.png)
|
||||
161
java/踩坑记录/Synchronized 锁在 Spring 事务管理下,为啥还线程不安全.md
Normal file
@ -0,0 +1,161 @@
|
||||
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [www.likecs.com](https://www.likecs.com/show-204940792.html)
|
||||
|
||||
> 开启 10000 个线程,每个线程给员工表的 money 字段【初始值是 0】加 1,没有使用悲观锁和乐观锁,但是在业务层方法上加了 synchronized 关键字,问题是代码执行完毕后数据库中的 money 字段不是......
|
||||
|
||||
> 开启 10000 个线程,每个线程给员工表的 money 字段【初始值是 0】加 1,没有使用悲观锁和乐观锁,但是在业务层方法上加了 synchronized 关键字,问题是代码执行完毕后数据库中的 money 字段不是 10000,而是小于 10000 问题出在哪里?
|
||||
|
||||
Service 层代码:
|
||||
|
||||

|
||||
|
||||
SQL 代码 (没有加悲观 / 乐观锁):
|
||||
|
||||

|
||||
|
||||
用 1000 个线程跑代码:
|
||||
|
||||

|
||||
|
||||
简单来说:多线程跑一个使用 **synchronized** 关键字修饰的方法,方法内操作的是数据库,按正常逻辑应该最终的值是 1000,但经过多次测试,结果是**低于** 1000。这是为什么呢?
|
||||
|
||||
既然测试出来的结果是低于 1000,那说明这段代码**不是线程安全**的。不是线程安全的,那问题出现在哪呢?众所周知,synchronized 方法能够保证所修饰的代码块、方法保证有序性、原子性、可见性。
|
||||
|
||||
讲道理,以上的代码跑起来,问题中 Service 层的 increaseMoney() 是有序的、原子的、可见的,所以**断定**跟 synchronized 应该没关系。
|
||||
|
||||
(参考我之前写过的 synchronize 锁笔记:Java 锁机制了解一下)
|
||||
|
||||
既然 Java 层面上找不到原因,那分析一下数据库层面的吧 (因为方法内操作的是数据库)。在 increaseMoney() 方法前加了 @Transcational 注解,说明这个方法是带有**事务**的。事务能保证同组的 SQL 要么同时成功,要么同时失败。讲道理,如果没有报错的话,应该每个线程都对 money 值进行 + 1。从理论上来说,结果应该是 1000 的才对。
|
||||
|
||||
(参考我之前写过的 Spring 事务:一文带你看懂 Spring 事务!)
|
||||
|
||||
根据上面的分析,我怀疑是**提问者没测试好** (hhhh,逃),于是我也跑去测试了一下,发现是以提问者的方式来使用**是真的有问题**。
|
||||
|
||||
首先贴一下我的测试代码:
|
||||
|
||||
```java
|
||||
@RestController
|
||||
public class EmployeeController {
|
||||
@Autowired
|
||||
private EmployeeService employeeService;
|
||||
@RequestMapping("/add")
|
||||
public void addEmployee() {
|
||||
for (int i = 0; i < 1000; i++) {
|
||||
new Thread(() -> employeeService.addEmployee()).start();
|
||||
}
|
||||
}
|
||||
}
|
||||
@Service
|
||||
public class EmployeeService {
|
||||
@Autowired
|
||||
private EmployeeRepository employeeRepository;
|
||||
@Transactional
|
||||
public synchronized void addEmployee() {
|
||||
// 查出ID为8的记录,然后每次将年龄增加一
|
||||
Employee employee = employeeRepository.getOne(8);
|
||||
System.out.println(employee);
|
||||
Integer age = employee.getAge();
|
||||
employee.setAge(age + 1);
|
||||
employeeRepository.save(employee);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
|
||||
简单地打印了每次拿到的 employee 值,并且拿到了 SQL 执行的顺序,如下 (贴出小部分):
|
||||
|
||||

|
||||
|
||||
从打印的情况我们可以得出:多线程情况下并**没有串行**执行 addEmployee() 方法。这就导致对同一个值做**重复**的修改,所以最终的数值比 1000 要少。
|
||||
|
||||
发现并不是**同步**执行的,于是我就怀疑 synchronized 关键字和 Spring 肯定有点冲突。于是根据这两个关键字搜了一下,找到了问题所在。
|
||||
|
||||
我们知道 Spring 事务的底层是 Spring AOP,而 Spring AOP 的底层是动态代理技术。跟大家一起回顾一下动态代理:
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
// 目标对象
|
||||
Object target ;
|
||||
Proxy.newProxyInstance(ClassLoader.getSystemClassLoader(), Main.class, new InvocationHandler() {
|
||||
@Override
|
||||
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
|
||||
// 但凡带有@Transcational注解的方法都会被拦截
|
||||
// 1... 开启事务
|
||||
method.invoke(target);
|
||||
// 2... 提交事务
|
||||
return null;
|
||||
}
|
||||
|
||||
});
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
|
||||
(详细请参考我之前写过的动态代理:给女朋友讲解什么是代理模式)
|
||||
|
||||
实际上 Spring 做的处理跟以上的思路是一样的,我们可以看一下 TransactionAspectSupport 类中 invokeWithinTransaction():
|
||||
|
||||

|
||||
|
||||
调用方法**前**开启事务,调用方法**后**提交事务
|
||||
|
||||

|
||||
|
||||
在多线程环境下,就可能会出现:**方法执行完了 (synchronized 代码块执行完了),事务还没提交,别的线程可以进入被 synchronized 修饰的方法,再读取的时候,读到的是还没提交事务的数据,这个数据不是最新的**,所以就出现了这个问题。
|
||||
|
||||

|
||||
|
||||
从上面我们可以发现,问题所在是因为 @Transcational 注解和 synchronized 一起使用了,**加锁的范围没有包括到整个事务**。所以我们可以这样做:
|
||||
|
||||
新建一个名叫 SynchronizedService 类,让其去调用 addEmployee() 方法,整个代码如下:
|
||||
|
||||
```java
|
||||
@RestController
|
||||
public class EmployeeController {
|
||||
@Autowired
|
||||
private SynchronizedService synchronizedService ;
|
||||
@RequestMapping("/add")
|
||||
public void addEmployee() {
|
||||
for (int i = 0; i < 1000; i++) {
|
||||
new Thread(() -> synchronizedService.synchronizedAddEmployee()).start();
|
||||
}
|
||||
}
|
||||
}
|
||||
// 新建的Service类
|
||||
@Service
|
||||
public class SynchronizedService {
|
||||
@Autowired
|
||||
private EmployeeService employeeService ;
|
||||
|
||||
// 同步
|
||||
public synchronized void synchronizedAddEmployee() {
|
||||
employeeService.addEmployee();
|
||||
}
|
||||
}
|
||||
@Service
|
||||
public class EmployeeService {
|
||||
@Autowired
|
||||
private EmployeeRepository employeeRepository;
|
||||
|
||||
@Transactional
|
||||
public void addEmployee() {
|
||||
// 查出ID为8的记录,然后每次将年龄增加一
|
||||
Employee employee = employeeRepository.getOne(8);
|
||||
System.out.println(Thread.currentThread().getName() + employee);
|
||||
Integer age = employee.getAge();
|
||||
employee.setAge(age + 1);
|
||||
employeeRepository.save(employee);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
|
||||
我们将 synchronized 锁的范围**包含到整个 Spring 事务上**,这就不会出现线程安全的问题了。在测试的时候,我们可以发现 1000 个线程跑起来**比之前要慢得多**,当然我们的数据是正确的:
|
||||
|
||||

|
||||
|
||||
可以发现的是,虽然说 Spring 事务用起来我们是非常方便的,但如果不了解一些 Spring 事务的细节,很多时候出现 Bug 了就百思不得其解。还是得继续加油努力呀~~~
|
||||
|
||||
笔者注:这个问题的核心是 synchronized 方法虽然能实现方法的同步,但是却未能实现数据库操作的同步,因为 synchronized 推出时事务还没有提交,这个时候有可能有其他线程进入该方法,如果在上一事务未提交前就读取数据,那么此时读取的数据就会有误!!!
|
||||
BIN
java/踩坑记录/assets/img-167247830648280.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 7.9 KiB |
BIN
java/踩坑记录/assets/img-167247830876683.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 7.2 KiB |
BIN
java/踩坑记录/assets/img-167247835317986.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 25 KiB |
BIN
java/踩坑记录/assets/img-167247836291889.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
BIN
java/踩坑记录/assets/img-167247836502092.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
BIN
java/踩坑记录/assets/img-167247836743495.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 16 KiB |
BIN
java/踩坑记录/assets/img-167247837669598.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.8 KiB |
BIN
java/踩坑记录/assets/img.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 11 KiB |
BIN
ubuntu/assets/1643267257621244.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 107 KiB |
BIN
ubuntu/assets/1643267285121077.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 222 KiB |
BIN
ubuntu/assets/1643267320249485.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 219 KiB |
BIN
ubuntu/assets/1643267361627502.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 176 KiB |
BIN
ubuntu/assets/2022012713362496593.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 15 KiB |
82
ubuntu/怎样修改 linux 时区.md
Normal file
@ -0,0 +1,82 @@
|
||||
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [m.php.cn](https://m.php.cn/article/488386.html)
|
||||
|
||||
> 方法:1、利用 “sudo rm -f /etc/localtime” 等命令修改系统时区;2、利用 Systemd 更改 linux 系统时区,语法为“sudo timedatectl set-timezone '时区'”。
|
||||
|
||||
> 方法:1、利用 “sudo rm -f /etc/localtime” 等命令修改系统时区;2、利用 Systemd 更改 linux 系统时区,语法为“sudo timedatectl set-timezone '时区'”。
|
||||
|
||||

|
||||
|
||||
本教程操作环境:linux7.3 系统、Dell G3 电脑。
|
||||
|
||||
怎样修改 linux 时区
|
||||
-------------
|
||||
|
||||
如果你的 Linux 系统时区配置不正确,必需要手动调整到正确的当地时区。NTP 对时间的同步处理只计算当地时间与 UTC 时间的偏移量,因此配置一个 NTP 对时间进行同步并不能解决时区不正确的问题。所以大家在用了国外云计算服务商如 Microsoft Azure 或其它 VPS、虚拟机时,需要注意是否与中国大陆的时区一致。
|
||||
|
||||
查看 Linux 当前时区
|
||||
|
||||
你可以使用如下命令非常容易地就查看到 Linux 系统的当前时区:
|
||||
|
||||
```
|
||||
date
|
||||
ls -l /etc/localtime
|
||||
```
|
||||
|
||||

|
||||
|
||||
获取时区 TZ 值
|
||||
|
||||
要更改 Linux 系统时区首先得获知你所当地时区的 TZ 值,使用 tzselect 命令即可查看并选择已安装的时区文件。
|
||||
|
||||
执行 tzselect 命令
|
||||
|
||||

|
||||
|
||||
通过向导选择你所在大洲、国家和城市
|
||||
|
||||
tzselect 最终将以 Posix TZ 格式(例如 Asia/Shanghai)输出你所在的时区值,将此记录下来。
|
||||
|
||||

|
||||
|
||||
**更改每个用户的时区**
|
||||
|
||||
Linux 用户一个多用户系统,每个用户都可以配置自己所需的时区,你可以为自己新增一个 TZ 环境变量:
|
||||
|
||||
```
|
||||
export TZ='Asia/Shanghai'
|
||||
```
|
||||
|
||||
执行完成之后需要重新登录系统或刷新 ~/.bashrc 生效。
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
**更改 Linux 系统时区**
|
||||
|
||||
要更改 Linux 系统整个系统范围的时区可以使用如下命令:
|
||||
|
||||
```
|
||||
sudo rm -f /etc/localtime
|
||||
sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
|
||||
```
|
||||
|
||||
注意:/usr/share/zoneinfo/Asia/Shanghai 中的具体时区请用自己获取到的 TZ 值进行替换。
|
||||
|
||||
**使用 Systemd 更改 Linux 系统时区**
|
||||
|
||||
如果你使用的 Linux 系统使用 Systemd,还可以使用 timedatectl 命令来更改 Linux 系统范围的时区。在 Systemd 下有一个名为 systemd-timedated 的系统服务负责调整系统时钟和时区,我们可以使用 timedatectl 命令对此系统服务进行配置。
|
||||
|
||||
```
|
||||
sudo timedatectl set-timezone 'Asia/Shanghai'
|
||||
```
|
||||
|
||||

|
||||
|
||||
相关推荐:《[Linux 视频教程](http://www.php.cn/course/list/33.html)》
|
||||
|
||||
以上就是怎样修改 linux 时区的详细内容,更多请关注 php 中文网其它相关文章!
|
||||
|
||||
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系 admin@php.cn 核实处理。
|
||||
|
||||
> 广告:[Linux 视频教程零基础入门到精通](https://s.click.taobao.com/OSVvKWu)
|
||||
{kind=link}
|
Before Width: | Height: | Size: 25 KiB After Width: | Height: | Size: 25 KiB |
{kind=link}
|
Before Width: | Height: | Size: 56 KiB After Width: | Height: | Size: 56 KiB |
{kind=link}
|
Before Width: | Height: | Size: 36 KiB After Width: | Height: | Size: 36 KiB |
{kind=link}
|
Before Width: | Height: | Size: 224 KiB After Width: | Height: | Size: 224 KiB |
{kind=link}
|
Before Width: | Height: | Size: 37 KiB After Width: | Height: | Size: 37 KiB |
{kind=link}
|
Before Width: | Height: | Size: 37 KiB After Width: | Height: | Size: 37 KiB |
{kind=link}
|
Before Width: | Height: | Size: 68 KiB After Width: | Height: | Size: 68 KiB |
{kind=link}
|
Before Width: | Height: | Size: 20 KiB After Width: | Height: | Size: 20 KiB |
{kind=link}
|
Before Width: | Height: | Size: 17 KiB After Width: | Height: | Size: 17 KiB |
{kind=link}
|
Before Width: | Height: | Size: 9.5 KiB After Width: | Height: | Size: 9.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 23 KiB After Width: | Height: | Size: 23 KiB |
{kind=link}
|
Before Width: | Height: | Size: 47 KiB After Width: | Height: | Size: 47 KiB |
@ -10,7 +10,7 @@
|
||||

|
||||
|
||||
2. 下图可以看到,硬盘空间增大为 53.7GB,在设备那里可以看到有两个分区,sda1 跟 sda2(请忽略 sda3)。接下来增加一个分区。
|
||||

|
||||

|
||||
|
||||
键入命令:`fdish /dev/sda`
|
||||
|
||||
@ -70,7 +70,3 @@
|
||||
[http://blog.csdn.net/junglyfine/article/details/4974269](http://blog.csdn.net/junglyfine/article/details/4974269)
|
||||
|
||||
[http://www.linuxidc.com/Linux/2014-06/103839p4.htm](http://www.linuxidc.com/Linux/2014-06/103839p4.htm)
|
||||
|
||||
------20180409 更新 ----------------
|
||||
|
||||
最近又遇到要扩容的 centos 虚拟机,结果发现不能在增加分区了,才想起来当初装 centos 虚拟机的时候,手动分区分了太多区了,而一个系统只能挂 4 个分区。结果没办法时间紧重新装了一个,弄了整整一天!!回去要好好补下 linux 的知识,做一篇笔记。
|
||||
{kind=link}
|
Before Width: | Height: | Size: 35 KiB After Width: | Height: | Size: 35 KiB |
{kind=link}
|
Before Width: | Height: | Size: 141 KiB After Width: | Height: | Size: 141 KiB |
{kind=link}
|
Before Width: | Height: | Size: 40 KiB After Width: | Height: | Size: 40 KiB |
{kind=link}
|
Before Width: | Height: | Size: 92 KiB After Width: | Height: | Size: 92 KiB |
{kind=link}
|
Before Width: | Height: | Size: 85 KiB After Width: | Height: | Size: 85 KiB |
{kind=link}
|
Before Width: | Height: | Size: 75 KiB After Width: | Height: | Size: 75 KiB |
{kind=link}
|
Before Width: | Height: | Size: 22 KiB After Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB After Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 37 KiB After Width: | Height: | Size: 37 KiB |
{kind=link}
|
Before Width: | Height: | Size: 72 KiB After Width: | Height: | Size: 72 KiB |
{kind=link}
|
Before Width: | Height: | Size: 72 KiB After Width: | Height: | Size: 72 KiB |
{kind=link}
|
Before Width: | Height: | Size: 56 KiB After Width: | Height: | Size: 56 KiB |
{kind=link}
|
Before Width: | Height: | Size: 49 KiB After Width: | Height: | Size: 49 KiB |
{kind=link}
|
Before Width: | Height: | Size: 81 KiB After Width: | Height: | Size: 81 KiB |
{kind=link}
|
Before Width: | Height: | Size: 50 KiB After Width: | Height: | Size: 50 KiB |
{kind=link}
|
Before Width: | Height: | Size: 43 KiB After Width: | Height: | Size: 43 KiB |
240
微服务/nacos/Nacos2.1 发布失败。请检查参数是否正确.md
Normal file
@ -0,0 +1,240 @@
|
||||
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [www.cnblogs.com](https://www.cnblogs.com/yanglei-xyz/p/16539139.html)
|
||||
|
||||
**现象:**nacos 2.1 版本在发布配置文件时报错:发布失败。请检查参数是否正确
|
||||
|
||||
**原因:**2.0 版本的 sql 脚本在 2.1 的时候做了调整
|
||||
|
||||
**解决:**官网 2.1 链接 (下载下来,打开 conf 里面的 nacos-mysql.sql,复制导入 msyql 即可):
|
||||
|
||||
https://github.rc1844.workers.dev/alibaba/nacos/releases/download/2.1.0/nacos-server-2.1.0.zip
|
||||
|
||||
下载好的 sql 文件:
|
||||
|
||||
[](javascript:void(0); "复制代码")
|
||||
|
||||
```
|
||||
/*
|
||||
* Copyright 1999-2018 Alibaba Group Holding Ltd.
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
/******************************************/
|
||||
/* 数据库全名 = nacos_config */
|
||||
/* 表名称 = config_info */
|
||||
/******************************************/
|
||||
CREATE TABLE `config_info` (
|
||||
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
|
||||
`group_id` varchar(255) DEFAULT NULL,
|
||||
`content` longtext NOT NULL COMMENT 'content',
|
||||
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
|
||||
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
`src_user` text COMMENT 'source user',
|
||||
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
|
||||
`app_name` varchar(128) DEFAULT NULL,
|
||||
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
|
||||
`c_desc` varchar(256) DEFAULT NULL,
|
||||
`c_use` varchar(64) DEFAULT NULL,
|
||||
`effect` varchar(64) DEFAULT NULL,
|
||||
`type` varchar(64) DEFAULT NULL,
|
||||
`c_schema` text,
|
||||
`encrypted_data_key` text NOT NULL COMMENT '秘钥',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uk_configinfo_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info';
|
||||
|
||||
/******************************************/
|
||||
/* 数据库全名 = nacos_config */
|
||||
/* 表名称 = config_info_aggr */
|
||||
/******************************************/
|
||||
CREATE TABLE `config_info_aggr` (
|
||||
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
|
||||
`group_id` varchar(255) NOT NULL COMMENT 'group_id',
|
||||
`datum_id` varchar(255) NOT NULL COMMENT 'datum_id',
|
||||
`content` longtext NOT NULL COMMENT '内容',
|
||||
`gmt_modified` datetime NOT NULL COMMENT '修改时间',
|
||||
`app_name` varchar(128) DEFAULT NULL,
|
||||
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uk_configinfoaggr_datagrouptenantdatum` (`data_id`,`group_id`,`tenant_id`,`datum_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='增加租户字段';
|
||||
|
||||
|
||||
/******************************************/
|
||||
/* 数据库全名 = nacos_config */
|
||||
/* 表名称 = config_info_beta */
|
||||
/******************************************/
|
||||
CREATE TABLE `config_info_beta` (
|
||||
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
|
||||
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
|
||||
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
|
||||
`content` longtext NOT NULL COMMENT 'content',
|
||||
`beta_ips` varchar(1024) DEFAULT NULL COMMENT 'betaIps',
|
||||
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
|
||||
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
`src_user` text COMMENT 'source user',
|
||||
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
|
||||
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
|
||||
`encrypted_data_key` text NOT NULL COMMENT '秘钥',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uk_configinfobeta_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_beta';
|
||||
|
||||
/******************************************/
|
||||
/* 数据库全名 = nacos_config */
|
||||
/* 表名称 = config_info_tag */
|
||||
/******************************************/
|
||||
CREATE TABLE `config_info_tag` (
|
||||
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
|
||||
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
|
||||
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
|
||||
`tag_id` varchar(128) NOT NULL COMMENT 'tag_id',
|
||||
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
|
||||
`content` longtext NOT NULL COMMENT 'content',
|
||||
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
|
||||
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
`src_user` text COMMENT 'source user',
|
||||
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uk_configinfotag_datagrouptenanttag` (`data_id`,`group_id`,`tenant_id`,`tag_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_tag';
|
||||
|
||||
/******************************************/
|
||||
/* 数据库全名 = nacos_config */
|
||||
/* 表名称 = config_tags_relation */
|
||||
/******************************************/
|
||||
CREATE TABLE `config_tags_relation` (
|
||||
`id` bigint(20) NOT NULL COMMENT 'id',
|
||||
`tag_name` varchar(128) NOT NULL COMMENT 'tag_name',
|
||||
`tag_type` varchar(64) DEFAULT NULL COMMENT 'tag_type',
|
||||
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
|
||||
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
|
||||
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
|
||||
`nid` bigint(20) NOT NULL AUTO_INCREMENT,
|
||||
PRIMARY KEY (`nid`),
|
||||
UNIQUE KEY `uk_configtagrelation_configidtag` (`id`,`tag_name`,`tag_type`),
|
||||
KEY `idx_tenant_id` (`tenant_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_tag_relation';
|
||||
|
||||
/******************************************/
|
||||
/* 数据库全名 = nacos_config */
|
||||
/* 表名称 = group_capacity */
|
||||
/******************************************/
|
||||
CREATE TABLE `group_capacity` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
|
||||
`group_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Group ID,空字符表示整个集群',
|
||||
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
|
||||
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
|
||||
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
|
||||
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数,,0表示使用默认值',
|
||||
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
|
||||
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
|
||||
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uk_group_id` (`group_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='集群、各Group容量信息表';
|
||||
|
||||
/******************************************/
|
||||
/* 数据库全名 = nacos_config */
|
||||
/* 表名称 = his_config_info */
|
||||
/******************************************/
|
||||
CREATE TABLE `his_config_info` (
|
||||
`id` bigint(64) unsigned NOT NULL,
|
||||
`nid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
|
||||
`data_id` varchar(255) NOT NULL,
|
||||
`group_id` varchar(128) NOT NULL,
|
||||
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
|
||||
`content` longtext NOT NULL,
|
||||
`md5` varchar(32) DEFAULT NULL,
|
||||
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
|
||||
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
|
||||
`src_user` text,
|
||||
`src_ip` varchar(50) DEFAULT NULL,
|
||||
`op_type` char(10) DEFAULT NULL,
|
||||
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
|
||||
`encrypted_data_key` text NOT NULL COMMENT '秘钥',
|
||||
PRIMARY KEY (`nid`),
|
||||
KEY `idx_gmt_create` (`gmt_create`),
|
||||
KEY `idx_gmt_modified` (`gmt_modified`),
|
||||
KEY `idx_did` (`data_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='多租户改造';
|
||||
|
||||
|
||||
/******************************************/
|
||||
/* 数据库全名 = nacos_config */
|
||||
/* 表名称 = tenant_capacity */
|
||||
/******************************************/
|
||||
CREATE TABLE `tenant_capacity` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
|
||||
`tenant_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Tenant ID',
|
||||
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
|
||||
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
|
||||
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
|
||||
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数',
|
||||
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
|
||||
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
|
||||
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uk_tenant_id` (`tenant_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='租户容量信息表';
|
||||
|
||||
|
||||
CREATE TABLE `tenant_info` (
|
||||
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`kp` varchar(128) NOT NULL COMMENT 'kp',
|
||||
`tenant_id` varchar(128) default '' COMMENT 'tenant_id',
|
||||
`tenant_name` varchar(128) default '' COMMENT 'tenant_name',
|
||||
`tenant_desc` varchar(256) DEFAULT NULL COMMENT 'tenant_desc',
|
||||
`create_source` varchar(32) DEFAULT NULL COMMENT 'create_source',
|
||||
`gmt_create` bigint(20) NOT NULL COMMENT '创建时间',
|
||||
`gmt_modified` bigint(20) NOT NULL COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uk_tenant_info_kptenantid` (`kp`,`tenant_id`),
|
||||
KEY `idx_tenant_id` (`tenant_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='tenant_info';
|
||||
|
||||
CREATE TABLE `users` (
|
||||
`username` varchar(50) NOT NULL PRIMARY KEY,
|
||||
`password` varchar(500) NOT NULL,
|
||||
`enabled` boolean NOT NULL
|
||||
);
|
||||
|
||||
CREATE TABLE `roles` (
|
||||
`username` varchar(50) NOT NULL,
|
||||
`role` varchar(50) NOT NULL,
|
||||
UNIQUE INDEX `idx_user_role` (`username` ASC, `role` ASC) USING BTREE
|
||||
);
|
||||
|
||||
CREATE TABLE `permissions` (
|
||||
`role` varchar(50) NOT NULL,
|
||||
`resource` varchar(255) NOT NULL,
|
||||
`action` varchar(8) NOT NULL,
|
||||
UNIQUE INDEX `uk_role_permission` (`role`,`resource`,`action`) USING BTREE
|
||||
);
|
||||
|
||||
INSERT INTO users (username, password, enabled) VALUES ('nacos', '$2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu', TRUE);
|
||||
|
||||
INSERT INTO roles (username, role) VALUES ('nacos', 'ROLE_ADMIN');
|
||||
|
||||
```
|
||||
|
||||
[](javascript:void(0); "复制代码")
|
||||
137
微服务/seata/Docker 安装 Seata 分布式事务.md
Normal file
@ -0,0 +1,137 @@
|
||||
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [developer.aliyun.com](https://developer.aliyun.com/article/913897)
|
||||
|
||||
> Docker 安装 Seata 分布式事务
|
||||
|
||||
1、简介
|
||||
----
|
||||
|
||||
之前已经对分布式事务 Seata 做了详细介绍,可参考:
|
||||
[分布式事务解决方案:Spring Cloud + Nacos + Seata 整合](https://yunfan.blog.csdn.net/article/details/123140907)
|
||||
|
||||
接下来直接上手,Docker 安装部署 Seata。
|
||||
|
||||
2、下载镜像
|
||||
------
|
||||
|
||||
```
|
||||
docker pull seataio/seata-server:1.4.2
|
||||
|
||||
```
|
||||
|
||||
3、启动容器
|
||||
------
|
||||
|
||||
```
|
||||
docker run -d --name seata-server -p 8091:8091 seataio/seata-server:1.4.2
|
||||
|
||||
```
|
||||
|
||||
4、拷贝文件
|
||||
------
|
||||
|
||||
```
|
||||
docker cp seata-server:/seata-server /docker-data/seata
|
||||
|
||||
```
|
||||
|
||||
5、修改配置文件
|
||||
--------
|
||||
|
||||
(1)修改配置文件 / docker-data/seata/resources/registry.conf,改为 Nacos 信息。
|
||||
|
||||
```
|
||||
registry {
|
||||
|
||||
type = "nacos"
|
||||
|
||||
nacos {
|
||||
application = "seata-server"
|
||||
serverAddr = "127.0.0.1:8848"
|
||||
group = "SEATA_GROUP"
|
||||
namespace = ""
|
||||
cluster = "default"
|
||||
username = "nacos"
|
||||
password = "nacos"
|
||||
}
|
||||
|
||||
......
|
||||
|
||||
config {
|
||||
|
||||
type = "nacos"
|
||||
|
||||
nacos {
|
||||
serverAddr = "127.0.0.1:8848"
|
||||
namespace = ""
|
||||
group = "SEATA_GROUP"
|
||||
username = "nacos"
|
||||
password = "nacos"
|
||||
dataId = "seataServer.properties"
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
(2)修改配置文件 / docker-data/seata/resources/file.conf,改为 DB 信息。
|
||||
|
||||
```
|
||||
store {
|
||||
|
||||
mode = "db"
|
||||
|
||||
......
|
||||
|
||||
|
||||
db {
|
||||
|
||||
datasource = "druid"
|
||||
|
||||
dbType = "mysql"
|
||||
driverClassName = "com.mysql.cj.jdbc.Driver"
|
||||
|
||||
url = "jdbc:mysql://localhost:3306/seata?rewriteBatchedStatements=true"
|
||||
user = "root"
|
||||
password = "root"
|
||||
minConn = 5
|
||||
maxConn = 100
|
||||
globalTable = "global_table"
|
||||
branchTable = "branch_table"
|
||||
lockTable = "lock_table"
|
||||
queryLimit = 100
|
||||
maxWait = 5000
|
||||
}
|
||||
......
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
6、停掉旧容器
|
||||
-------
|
||||
|
||||
```
|
||||
docker stop seata-server
|
||||
docker rm seata-server
|
||||
|
||||
```
|
||||
|
||||
7、启动新容器
|
||||
-------
|
||||
|
||||
```
|
||||
docker run -d \
|
||||
--restart always \
|
||||
--name seata-server \
|
||||
-p 8091:8091 \
|
||||
-v /docker-data/seata:/seata-server \
|
||||
-e SEATA_IP=外网IP \
|
||||
-e SEATA_PORT=8091 \
|
||||
seataio/seata-server:1.4.2
|
||||
|
||||
```
|
||||
|
||||
**注意:** 遇到的坑,如果是部署云服务器,没有设置 SEATA_IP,默认注册的是 docker 的内网 ip,seata 启动虽然没有问题,但是微服务项目启动连接时,会报错 can not register RM,err:can not connect to services-server.
|
||||
|
||||
8、查看 Nacos 注册情况
|
||||
---------------
|
||||
|
||||

|
||||
{kind=link}
|
After Width: | Height: | Size: 55 KiB |
{kind=link}
|
After Width: | Height: | Size: 55 KiB |
BIN
数据结构/图/assets/1587477099286.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 78 KiB |
BIN
数据结构/图/assets/1587477311455-16724777105769-167247771235811.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
BIN
数据结构/图/assets/1587477311455-16724777105769.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
BIN
数据结构/图/assets/1587477311455.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
BIN
数据结构/图/assets/1587477435893.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 52 KiB |
BIN
数据结构/图/assets/1587477556167.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 49 KiB |
BIN
数据结构/图/assets/1587477763188.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 52 KiB |
BIN
数据结构/图/assets/1587477964075.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 35 KiB |
BIN
数据结构/图/assets/1587478052256.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 64 KiB |
BIN
数据结构/图/assets/1587478135713.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 65 KiB |
462
数据结构/图/图的存储结构之邻接矩阵和邻接表(Java 实现).md
Normal file
@ -0,0 +1,462 @@
|
||||
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [www.suibibk.com](https://www.suibibk.com/topic/702275250418614272)
|
||||
|
||||
> 一、图的存储结构讨论对于线性表来说,是一对一的关系,所以用数组或者链表均可以简单存放。
|
||||
|
||||
### 一、图的存储结构讨论
|
||||
|
||||
> 对于线性表来说,是一对一的关系,所以用数组或者链表均可以简单存放。
|
||||
> 对于树结构是一对多的关系,所以我们要将数组和链表的特性结合在一起才能更好的存放。
|
||||
> 对于图来说,是多对多的情况,另外图上的任意一个顶点都可以被看做是第一个顶点,任一顶点的邻接点之间也不存在次序关系
|
||||
|
||||
**如下图:实际是一个图结构,只不过顶点位置不同。**
|
||||

|
||||
|
||||
> 由于图的结构复杂,任意两个顶点之间都可能存在联系,因此无法以数据元素在内存中的物理位置来表示元素之间的关系,也就是说,图不可能用简单的顺序存储结构来表示。内存物理位置是线性的,图的元素关系是平面的。
|
||||
>
|
||||
> 虽然我们可以向树结构中说到的那样使用多重链表,但是我们需要先确定最大的度,然后按照这个度最大的顶点设计结点结构,若是每个顶点的度数相差较大,就会造成大量的存储单元浪费。
|
||||
|
||||
### 二、图的存储结构(1)—- 邻接矩阵
|
||||
|
||||
> 考虑到图是由顶点和边(弧)两部分组成的,合在一起是比较困难的,那就很自然的考虑到分为两个结构来分别存储
|
||||
|
||||
顶点因为不区分大小,主次,所以用一个一维数组来存储时不错的选择。
|
||||
|
||||
> 而边或弧由于是顶点与顶点之间的关系,所以我们最好使用二维数组来存储,图的邻接矩阵存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
|
||||
|
||||

|
||||
|
||||
#### 1、无向图
|
||||
|
||||

|
||||
|
||||
```
|
||||
其中1表示两个顶点之间存在关系,0表示无关,不存在顶点间的边。
|
||||
```
|
||||
|
||||
> 对称矩阵:就是 n 阶矩阵满足 a[i][j]=a[j][i](0<=i,j<=n)。即从矩阵的左上角到右下角的主对角线为轴,右上角的源与左下角相对应的元都是相等的。
|
||||
|
||||
根据这个矩阵,我们可以很容易的知道图中的信息。
|
||||
|
||||
* 1. 我们要判定容易两顶点是否有边无边就非常容易了。
|
||||
* 2. 我们要知道某个顶点的度,其实就是这个顶点 vi 在邻接矩阵中第 i 行(或第 i 列)的元素之和。比如上图顶点 v1 的度就是 1+0+1+0=2
|
||||
* 3. 求顶点 vi 的所有邻接点就是将矩阵第 i 行元素扫描一遍,arc[i][j] 为 1 就是邻接点
|
||||
|
||||
#### 2、有向图
|
||||
|
||||
对于上面的无向图,二维对称矩阵似乎浪费了一半的空间。若是存放有向图,会更大程度利用起来空间
|
||||
|
||||

|
||||
|
||||
其中顶点数组是一样的和无向图,弧数组也是一个矩阵,但因为是有向图,所以这个矩阵并不对称:例如 v1->v0 有弧,arc[1][0]=1, 而 v0 到 v1 没有弧,所以 arc[0][1]=0。
|
||||
|
||||
另外有向图,要考虑入度和出度,顶点 v1 的入度为 1,正好是第 v1 列的各数之和,顶点 v1 的出度为 2,正好是第 v2 行的各数之和
|
||||
|
||||
#### 3、网
|
||||
|
||||
每条边上带有权的有向图就叫做网
|
||||
|
||||

|
||||
|
||||
这里‘∞’表示一个计算机允许的,大于所有边上权值的值
|
||||
|
||||
#### 4、Java 实现无向图、有向图、网的邻接矩阵创建
|
||||
|
||||
```
|
||||
public class G2 {
|
||||
public static void main(String[] args) {
|
||||
//1、无向图
|
||||
//定点数组vertex
|
||||
String[] v1 = new String[]{"V0","V1","V2","V3"};
|
||||
//矩阵表示边的关系edge 其中1表示两个顶点之间存在关系,0表示无关,不存在顶点间的边。
|
||||
int[][] e1 = new int[][] {
|
||||
{0,1,1,1},
|
||||
{1,0,1,0},
|
||||
{1,1,0,1},
|
||||
{1,0,1,0}
|
||||
};
|
||||
System.out.println("输出无向图:");
|
||||
for (int i = 0; i < v1.length; i++) {
|
||||
System.out.print(v1[i]+"\t");
|
||||
}
|
||||
System.out.println();
|
||||
for (int i = 0; i < v1.length; i++) {
|
||||
for (int j = 0; j < v1.length; j++) {
|
||||
System.out.print(e1[i][j]+"\t");
|
||||
}
|
||||
System.out.println();
|
||||
}
|
||||
System.out.println("--------------------");
|
||||
//2、有向图
|
||||
String[] v2 =new String[]{"V0","V1","V2","V3"};
|
||||
int[][] e2 = new int[][] {
|
||||
{0,0,0,1},
|
||||
{1,0,1,0},//V1的出度为2
|
||||
{1,1,0,0},//V2的出度为2
|
||||
{0,0,0,0}
|
||||
//V1的入度为1
|
||||
};
|
||||
System.out.println("输出有向图:");
|
||||
for (int i = 0; i < v2.length; i++) {
|
||||
System.out.print(v2[i]+"\t");
|
||||
}
|
||||
System.out.println();
|
||||
for (int i = 0; i < v2.length; i++) {
|
||||
for (int j = 0; j < v2.length; j++) {
|
||||
System.out.print(e2[i][j]+"\t");
|
||||
}
|
||||
System.out.println();
|
||||
}
|
||||
System.out.println("--------------------");
|
||||
//3、网,每条边上带有权的图就叫做网
|
||||
String[] v3 =new String[]{"V0","V1","V2","V3","V4"};
|
||||
//m表示不可达
|
||||
int m=65535;
|
||||
int[][] e3 = new int[][] {
|
||||
{0,m,m,m,6},
|
||||
{9,0,3,m,m},
|
||||
{2,m,0,5,m},
|
||||
{m,m,m,0,1},
|
||||
{m,m,m,m,0}
|
||||
};
|
||||
System.out.println("输出网:");
|
||||
for (int i = 0; i < v3.length; i++) {
|
||||
System.out.print(v3[i]+"\t");
|
||||
}
|
||||
System.out.println();
|
||||
for (int i = 0; i < v3.length; i++) {
|
||||
for (int j = 0; j < v3.length; j++) {
|
||||
System.out.print(e3[i][j]+"\t");
|
||||
}
|
||||
System.out.println();
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
代码中的图跟上面说的图一一对应,运行结果如下:
|
||||
|
||||
```
|
||||
输出无向图:
|
||||
V0 V1 V2 V3
|
||||
0 1 1 1
|
||||
1 0 1 0
|
||||
1 1 0 1
|
||||
1 0 1 0
|
||||
--------------------
|
||||
输出有向图:
|
||||
V0 V1 V2 V3
|
||||
0 0 0 1
|
||||
1 0 1 0
|
||||
1 1 0 0
|
||||
0 0 0 0
|
||||
--------------------
|
||||
输出网:
|
||||
V0 V1 V2 V3 V4
|
||||
0 65535 65535 65535 6
|
||||
9 0 3 65535 65535
|
||||
2 65535 0 5 65535
|
||||
65535 65535 65535 0 1
|
||||
65535 65535 65535 65535 0
|
||||
|
||||
```
|
||||
|
||||
### 三、图的存储结构(2)—- 邻接表
|
||||
|
||||
上面的邻接矩阵是一种不错的图存储结构,便于理解,但是当我们的边数相对于顶点较少的图,这种结构是存在对存储空间的极大的浪费。
|
||||

|
||||
|
||||
**我们可以考虑使用链表来动态分配空间,避免使用数组一次分配而造成空间浪费问题。**
|
||||
|
||||
同树中,孩子表示法,我们将结点存放入数组,对结点的孩子进行链式存储,不管有多少孩子,都不会存在空间浪费。这种思路也适用于图的存储。我们把这种数组与链表相结合的存储方法称为邻接表。
|
||||
|
||||
#### 邻接表处理办法
|
||||
|
||||
* 1. 图中顶点用一个一维数组。当然,顶点也可以用单链表来存储,不过数组可以较容易的读取顶点信息,更加方便。另外,对于顶点数组中,每个数据元素还需要存储指向第一个邻接点的指针,以便于查找该顶点的边信息
|
||||
|
||||
* 2. 图中每个顶点 vi 的所有邻接点构成一个线性表,由于邻接点的个数不定,所以用单链表存储,无向图称为顶点 vi 的边表,有向图则称为顶点 vi 作为弧尾的出边表
|
||||
|
||||
#### 1、无向图
|
||||
|
||||

|
||||
这样的结构,对于我们要获得图的相关信息也是很方便。比如:
|
||||
我们要获取某个顶点的度,就要去查找这个顶点的边表中结点的个数。
|
||||
我们要判断 vi 到 vj 是否存在边,只需要测试 vi 的边表链表中是否存在结点 vj 的下标 j 即可。
|
||||
我们若是要获取顶点的所有邻接点,就是对此顶点的边表进行遍历。
|
||||
|
||||
#### 2、有向图
|
||||
|
||||
有向图由于有方向,我们是以顶点为弧尾来存储边表的,这样很容易就可以得到每个顶点的出度。但是由于有时也需要确定顶点的入度或以顶点作为弧头的弧,我们可以建立一个有向图的逆邻接表,即对每个顶点 vi 都建立一个链接为 vi 为弧头的表。
|
||||

|
||||
|
||||
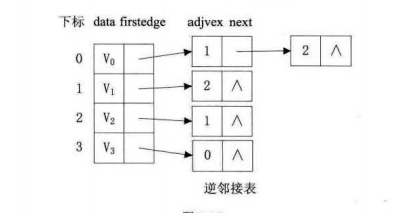
|
||||
|
||||
#### 3、带权值的网
|
||||
|
||||
们可以在边表结点定义中再增加一个 weight 数据域,存储权值信息即可。
|
||||
|
||||

|
||||
|
||||
#### 4、Java 实现无向图、有向图、网的邻接链表创建
|
||||
|
||||
首先我们看一下《算法导论》中关于图的邻接表的定义:图 G=(V,E) 的邻接表表示有一个包含 |V| 个列表的数组 Adj 所组成,其中每个列表对应于 V 中的一个顶点,对于每一个 u∈V,邻接表 Adj[u] 包含所有满足条件(u,v)∈E 的顶点 v,亦即,Adj[u] 包含图 G 中所有和顶点 u 相邻的顶点。(或者他也可能指向这些顶点的指针),**每个邻接表中的顶点一般以任意的顺序存储。**(注意一下这句话!)
|
||||
|
||||
这里的实现方法有多重多样,下面是按我的思路实现的代码示例,一般都会有两个对象,一个是顶点,如下:
|
||||
|
||||
```
|
||||
//定义定点
|
||||
class Vertex{
|
||||
String value;//顶点的值
|
||||
Edge firstEdge;//第一条边
|
||||
public Vertex(String value, Edge firstEdge) {
|
||||
super();
|
||||
this.value = value;
|
||||
this.firstEdge = firstEdge;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这里我们可已将顶点放在一个数组中,然后每个顶点都从第一条边衍生出去。当然可以按具体需求多加属性,比如顶点的出度也可以当做一个属性什么的,我这里就不加了!
|
||||
|
||||
然后定义边的对象:
|
||||
|
||||
```
|
||||
class Edge{
|
||||
String value;//该边对应的顶点
|
||||
int weight;//权重,无向图,有向图权重为0
|
||||
Edge next;//下一个边
|
||||
/**
|
||||
* 构建一条边 weight未0表示无向图或者有向图 不为0表示网
|
||||
* @param value
|
||||
* @param weight
|
||||
* @param next
|
||||
*/
|
||||
public Edge(String value, int weight, Edge next) {
|
||||
super();
|
||||
this.value = value;
|
||||
this.weight = weight;
|
||||
this.next = next;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
我这里因为要举无向图,有向图,网的例子,所以这个边就直接有权重,但是无向图,有向图的权重为 0。
|
||||
|
||||
然后下面是完整的代码,跟上面三个示例图对应:
|
||||
|
||||
```
|
||||
/**
|
||||
* 邻接链表
|
||||
* @author suibibk.com
|
||||
*/
|
||||
public class Graph {
|
||||
public int num;//顶点个数
|
||||
//顶点
|
||||
List<Vertex> vertexs;
|
||||
public Graph(int num) {
|
||||
this.num = num;
|
||||
//初始化图的大小
|
||||
vertexs = new ArrayList<Vertex>(num);
|
||||
}
|
||||
//插入顶点
|
||||
public void addVertex(String value) {
|
||||
vertexs.add(new Vertex(value, null));
|
||||
}
|
||||
//获取顶点
|
||||
public Vertex getVertex(String value) {
|
||||
for (int i = 0; i < num; i++) {
|
||||
if(vertexs.get(i).value.equals(value)) {
|
||||
return vertexs.get(i);
|
||||
}
|
||||
}
|
||||
return null;
|
||||
}
|
||||
/**
|
||||
* 添加无向图的边
|
||||
* @param vertex1 第一个顶点
|
||||
* @param vertex2 第二个顶点
|
||||
*/
|
||||
public void addUndigraphEdge(String vertex1,String vertex2) {
|
||||
//因为是无向图,所以就直接加入
|
||||
addEdgeByVertex(vertex1,vertex2,0);
|
||||
addEdgeByVertex(vertex2,vertex1,0);
|
||||
}
|
||||
/**
|
||||
* 添加有向图的边
|
||||
* @param start 开始节点
|
||||
* @param end 结束节点
|
||||
*/
|
||||
public void addDigraphEdge(String start,String end) {
|
||||
//因为是有向图,所以只有一条边
|
||||
addEdgeByVertex(start,end,0);
|
||||
}
|
||||
/**
|
||||
* 添加网的边
|
||||
* @param start 开始节点
|
||||
* @param end 结束节点
|
||||
* @param weight 权重
|
||||
*/
|
||||
public void addWebEdge(String start,String end,int weight) {
|
||||
//网就是有向图有权重
|
||||
addEdgeByVertex(start,end,weight);
|
||||
}
|
||||
/**
|
||||
* 添加一条由start-->end的边
|
||||
* @param start
|
||||
* @param end
|
||||
* @param weight 权重未0表示无向图或者有向图,部位0表示网
|
||||
*/
|
||||
private void addEdgeByVertex(String start,String end,int weight) {
|
||||
//1、找到第一个顶点
|
||||
Vertex v1 = this.getVertex(start);
|
||||
//2、检查这条边是否已经存在,已经存在就直接报错
|
||||
Edge firstEdge = v1.firstEdge;
|
||||
while(firstEdge!=null) {
|
||||
//获取这个边
|
||||
String value = firstEdge.value;
|
||||
if(end.equals(value)) {
|
||||
System.out.println("边"+start+"-->"+end+"已经加入,不可以再加入");
|
||||
return;
|
||||
}else {
|
||||
Edge next = firstEdge.next;
|
||||
firstEdge=next;
|
||||
}
|
||||
}
|
||||
//到这里就可以加入这一条边了
|
||||
firstEdge = v1.firstEdge;
|
||||
//到这里就可以加入这条边
|
||||
if(firstEdge==null) {
|
||||
firstEdge = new Edge(end,weight, null);
|
||||
v1.firstEdge=firstEdge;
|
||||
}else {
|
||||
//当前节点变为第一个节点
|
||||
Edge nowEdge = new Edge(end,weight, null);
|
||||
v1.firstEdge=nowEdge;
|
||||
nowEdge.next=firstEdge;
|
||||
}
|
||||
}
|
||||
/**
|
||||
* 输出图
|
||||
*/
|
||||
public void print() {
|
||||
for (int i = 0; i <num; i++) {
|
||||
Vertex vertex = vertexs.get(i);
|
||||
System.out.print(vertex.value+"-->");
|
||||
Edge edge = vertex.firstEdge;
|
||||
while(edge!=null) {
|
||||
System.out.print(edge.value+"["+edge.weight+"]");
|
||||
Edge next = edge.next;
|
||||
edge=next;
|
||||
if(next!=null) {
|
||||
System.out.print("-->");
|
||||
}else {
|
||||
System.out.print("-->∧");
|
||||
}
|
||||
}
|
||||
System.out.println();
|
||||
}
|
||||
}
|
||||
public static void main(String[] args) {
|
||||
//测试无向图
|
||||
Graph g = new Graph(4);
|
||||
g.addVertex("V0");
|
||||
g.addVertex("V1");
|
||||
g.addVertex("V2");
|
||||
g.addVertex("V3");
|
||||
//插入边:无向图
|
||||
g.addUndigraphEdge("V0", "V1");
|
||||
g.addUndigraphEdge("V1", "V2");
|
||||
g.addUndigraphEdge("V2", "V3");
|
||||
g.addUndigraphEdge("V3", "V0");
|
||||
g.addUndigraphEdge("V2", "V0");
|
||||
System.out.println("输出无向图:");
|
||||
g.print();
|
||||
System.out.println("------------");
|
||||
Graph g1 = new Graph(4);
|
||||
g1.addVertex("V0");
|
||||
g1.addVertex("V1");
|
||||
g1.addVertex("V2");
|
||||
g1.addVertex("V3");
|
||||
//插入边:有向图
|
||||
g1.addDigraphEdge("V0", "V3");
|
||||
g1.addDigraphEdge("V1", "V0");
|
||||
g1.addDigraphEdge("V1", "V2");
|
||||
g1.addDigraphEdge("V2", "V0");
|
||||
g1.addDigraphEdge("V2", "V1");
|
||||
System.out.println("输出有向图:");
|
||||
g1.print();
|
||||
System.out.println("----------");
|
||||
Graph g2 = new Graph(4);
|
||||
g2.addVertex("V0");
|
||||
g2.addVertex("V1");
|
||||
g2.addVertex("V2");
|
||||
g2.addVertex("V3");
|
||||
//插入边:有向图
|
||||
g2.addWebEdge("V0", "V4",6);
|
||||
g2.addWebEdge("V1", "V0",9);
|
||||
g2.addWebEdge("V1", "V2",3);
|
||||
g2.addWebEdge("V2", "V0",2);
|
||||
g2.addWebEdge("V2", "V3",5);
|
||||
g2.addWebEdge("V3", "V4",1);
|
||||
System.out.println("输出带权值的网:");
|
||||
g2.print();
|
||||
}
|
||||
}
|
||||
//定义定点
|
||||
class Vertex{
|
||||
String value;//顶点的值
|
||||
Edge firstEdge;//第一条边
|
||||
public Vertex(String value, Edge firstEdge) {
|
||||
super();
|
||||
this.value = value;
|
||||
this.firstEdge = firstEdge;
|
||||
}
|
||||
}
|
||||
class Edge{
|
||||
String value;//该边对应的顶点
|
||||
int weight;//权重,无向图,有向图权重为0
|
||||
Edge next;//下一个边
|
||||
/**
|
||||
* 构建一条边 weight未0表示无向图或者有向图 不为0表示网
|
||||
* @param value
|
||||
* @param weight
|
||||
* @param next
|
||||
*/
|
||||
public Edge(String value, int weight, Edge next) {
|
||||
super();
|
||||
this.value = value;
|
||||
this.weight = weight;
|
||||
this.next = next;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Copy 即可运行,结果如下:
|
||||
|
||||
```
|
||||
输出无向图:
|
||||
V0-->V2[0]-->V3[0]-->V1[0]-->∧
|
||||
V1-->V2[0]-->V0[0]-->∧
|
||||
V2-->V0[0]-->V3[0]-->V1[0]-->∧
|
||||
V3-->V0[0]-->V2[0]-->∧
|
||||
------------
|
||||
输出有向图:
|
||||
V0-->V3[0]-->∧
|
||||
V1-->V2[0]-->V0[0]-->∧
|
||||
V2-->V1[0]-->V0[0]-->∧
|
||||
V3-->
|
||||
----------
|
||||
输出带权值的网:
|
||||
V0-->V4[6]-->∧
|
||||
V1-->V2[3]-->V0[9]-->∧
|
||||
V2-->V3[5]-->V0[2]-->∧
|
||||
V3-->V4[1]-->∧
|
||||
|
||||
```
|
||||
|
||||
上面把添加变的操作抽取成了公共的方法!
|
||||
|
||||
完成!
|
||||